Welcome to Battleship AI
ABSTRACT
This project trains a neural network to play Battleship, the board game, by using an Open AI gym environment for training. All training was done against a random agent and progress is reported as average win percentage. The algorithm primarily used for training is PPO. Ater trying training with verious lengths and various rewards parameters, the best training parameters found are a 13M step training length, a reward for hitting a ship, sinking a ship, winning the game, and a negative reward for trying to hit a spot that has already been shot at. With these parameters for rewards, the network is able to play at about a 70% win rate against a random oponent. Given that the random opponent will sometimes get lucky and play particularly well, a 70% win rate is quite good, and suggests the network has learned to play the game with some level of skill.
INTRODUCTION
In this project, I teach a computer to play battleship. Since battleship is a technical game and the ideal move changes as the game progresses, it is interesting to see how well we are able to tach the AI to play. The main reason this is a challenging task is that we need advanced algorithms to learn how to play the game, if I want the AI to actually play well, and the learning technique needs to understand how to learn well. If an adult plays battleship against a toddler who makes moves randomly, the adult will win almost every time. My goal is to train the computer to play less like a toddler making random moves and more like a skilled adult; this is a challenging task. The fact that deep learning is a black box is a further difficulty since I cannot help the computer learn better since no one knows how it is learning exactly, and we only see performance. I hope to find that after training, the AI is able to play battleship well beyond that of a random player.
In terms of an ethical extension, as battleship is a game that mimics a military procedure, I talk about some of the ethical implications of AI being used for military purposes.
LITERATURE REVIEW
There are a few projects that have been done which talk teach AI to play board games. In the article, Measuring AI advancement through games, the authors discuss the progress of AI in terms of playing several different board games. Some of the games they look into are Chess, Pacman, Texas hold’em, Jeopardy, Atari, and Dota2. These games have all been conquered at some level, and most of them have an AI which can beat all human players. There is one game which is yet to be conquered and that game is Bridge. The article also talks to OpenAI and their platform, universe, to continue training AI for games and other projects.
Google has created an AI to play the board game, GO, and it has been able to beat some of the highest regarded GO players in the world. First it was able to beat Lee Sedol in 2016 and then in 2017 the AI beat GO grandmaster Ke Jie. In terms of AI and learning to play board games this was a huge accomplishment. The game was livestreamed on Youtube. The number of possible boards for GO is larger than the number of atoms in the universe.
In addition to GO, a board game that has been studied with AI is Ticket to Ride. In thier paper, Lee, Silva, Togelius, and Nealen discuss a few playing styles are taught and then analyzed to see how effective each is. They use the playing styles to look at what pieces of the game are most valuable in terms of winning. They find that certain cities are more important in order to win the game.
The research on AI and games is not all board games, and OpenAI ran a project for teams to compete to play hide and seek. the teams had to adapt to each other while they were playing. The games start crazily and frantic but finally, after many rounds, the hiders learn to lock out the seekers to win in general. The hider-teams had to learn to work together. They found some errors with the way they coded the physics, and it created some fun-to-watch results that would not be possible in a real game of hide and seek.
METHODS
In this project there are a few steps taken before the learning can take place. To begin, I used python to write a battleship game. After this, I then made this python program compatible with the openai gym environment, and used stable baselines3 reinforcement learning library for the implementaiton of the learning algorithm. The neural network was trained in pytorch.
The input to the network is a two-dimensional array which is coming from the python battleship program,and the output are actions (moves) which are represented as a one dimensional array.
In order to have the AI able to learn, I found a framework OpenAI (linked below) and, as it turns out, you must use classes for the AI to be able to learn. The first step to using the framework was therefore to turn the program I had written into a class. After this, I made my program compatible with the gym wrapper. First, I created the init function to define the action space and the observation space for the AI, and set a reward variable. I then made the makeObs function which computes an observation for the network and decides what info the network will use to make an action. I also make step, reset, and render functions to help with execution of the game and communicate with the network.
Stable baselines comes with a default neural network and the next step is training this network to play battleship. In terms of rewards, I tried a few different reward structures and saw different results, and these results are presented in the next section. One aspect I kept constant with rewards is a negative one reward for each time the network tries to launch an attack where they have already done so because once a spot has been hit it can never be hit again. Before we implemented this reward, all of trainings were below 50% average win rate, and after, we were able to train a network to perform at about a 70% win rate (results disussed more below). I tried both a PPO and a DQN algorithm for training, and ultimately decided to train the network with PPO since the results seemed more promising.
DISCUSSION
What was found initially, is that the AI we trained was not able to play much better than a random player, and when I looked at the graphed results of win rate, the win rate for the network was not higher than 50% against a random opponent. The graph below shows the win rate against a random opponent and you can see that the win percentage hovers around 50% but never improves higher, and this can be interpreted as the AI plays almost as well as a random opponent.

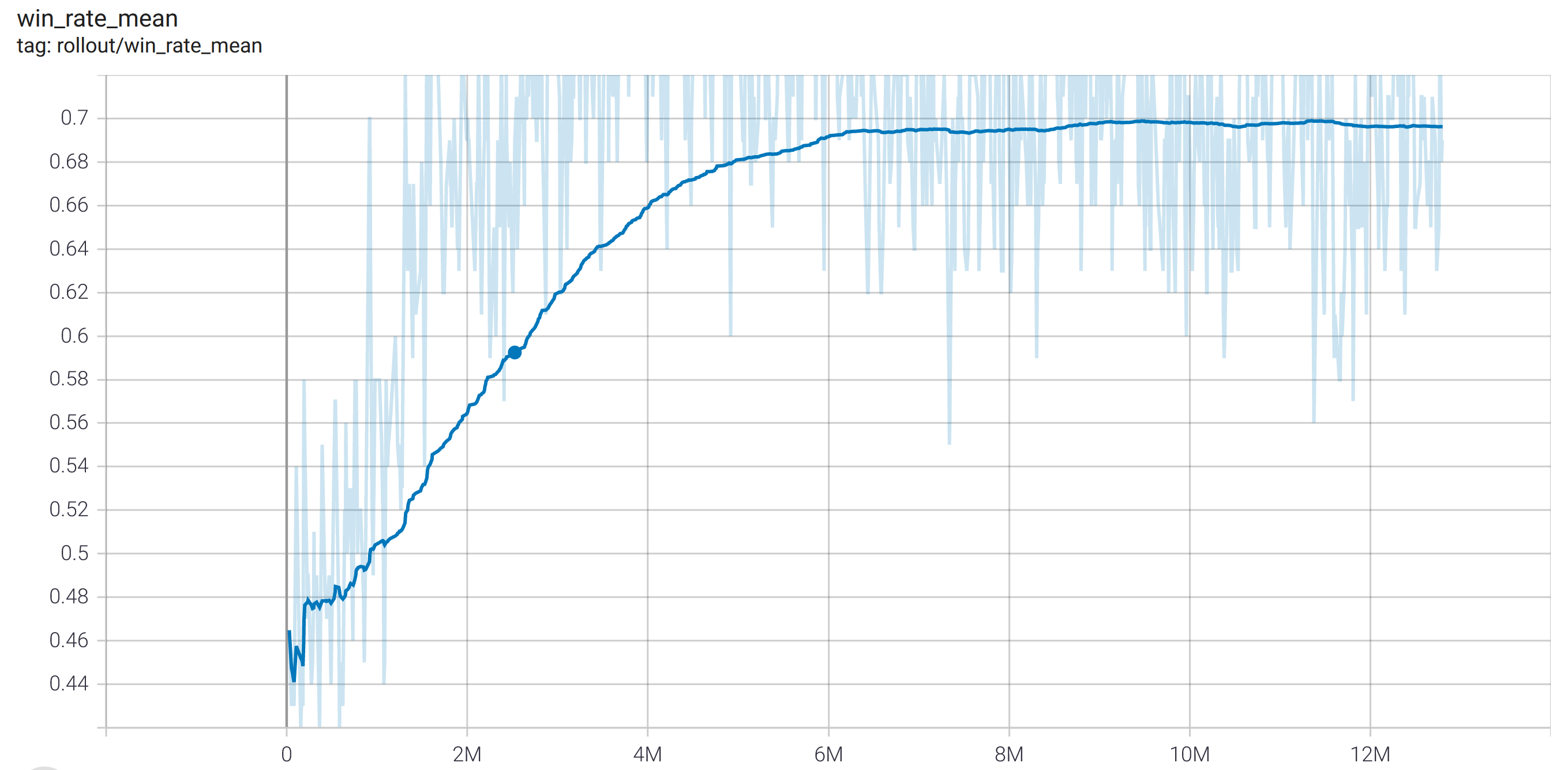
Although this is initially a disappointing result, it turned out to not be impossible to improve. I believe the poor initial results is due to the rewards allocation. In the game Battleship you only, as a human, get a reward at the end for winning, and initially I trained the network with only a reward for winning the game (and a negative reward for guessing a spot already guessed). However, when you play, there is a sense of happiness that comes as you hit a ship and as you sink your opponent’s ships, and for this reason I added in rewards for those aspects as well. I saw that when I tweaked these parameters the results changed, and thus it is a question of identifying the correct ratios of rewards. Once I tweaked various reward ratios between winning the game, sinking a ship, and hitting a ship, I was able to train the network and found about a 70% win rate against a random opponent. The average win rate during training is shown below, and you can see that from the begining until about 6M steps, the network’s performance increases until it reaches about 70% win rate. The graph is a bit noisy but you can notice that after about 1M mark, the win rate stays above 50% at all times which means the network is always playing better than randomly.
Battleship is a two-player game, but typically the actions of the other player are irrelevant to our strategy since it is not interactive. For the purpose of rewards, I therefore gave no negative rewards when the opponent was sinking our ships. However, in turn, the network seems to be confused when the game suddenly ended, and it seems that the network is not sure how to estimate how much time it has to sink all of the ships. There is an issue of the network trying to learn an optimal sinking strategy, but then being cut short and seemingly randomly so. I therefore tried a few cases where place a negative reward for the opponent sinking our ships, and for every ship the opponent hit we gave a reward of -.5. My hypothesis was that if the netowrk knows they are one ship away from loosing the game, there might be an all-or-nothing guessing strategy that is most beneficial here. Once I tried this strategy of rewards, the trained network had a win rate that was just higher than 50%, and the graph below shows the netowrk’s performance.

DIAGRAM OF BATTLESHIP
Battleship is a two player game and each player has two boards, for a total of four boards. The first board is the players own ships and they keep track of which are hit and which are still floating, and the second board is blank to begin and is where a player maps out all of the shots they have taken on their opponents board. The first board has four symbols, a ship, water, a sunk piece of ship, and a hit piece of water. The second board has two symbols, a hit or a miss. Below is an image that shows an example of the boards of one player before the game has begun.

(Image from https://www.mydraw.com/templates-scorecards-battleships)
ETHICS DISCUSSION
Battleship is a game in which you aim to sink your opponents’ ships by launching attacks. In this project, we looked at an AI who learned where to launch the attacks as to best defeat the opponent. However, if this was not a game and was AI for the military the stakes are quite a bit different.
Potential Detriments of using AI for military use:
A “miss” might mean firing into a civilian town instead of hitting a military base, and this is a high price to pay for a computer mistake. It is not easy to train the AI and consequences means lives lost. In economics we learned that the US government places each life at about US $125,000, but the US military budget is 1.92 trillion. If the military wants to run tests and only values lives at 125,000 they might be a little bit too quick to trust their AI, and I am not aware of any real ramifications in play for the military if a test goes wrong.
Benefits of using AI for military use:
There is a positive look that if AI can provide more accuracy than humans can in various situations, then we might actually avoid casualties and mistakes could happen much less, and there are many applications where technology has improved the military so far. For example, weapons, transportation, machines to carry items, robots to detect and robots that can shoot.
In conclusion:
AI however should be treated a bit differently since it is something that “thinks” and to the extent that we do not know exactly what a network has learned, we don’t know how the network will behave. It could be that for 100 days the network looks perfect and does what it should, but on the 101th day everything happens badly. There is no way to truly know why the change happened or what caused the good days in the first place. There are positives and negatives to using AI with regards to the US military, but I do believe we should approach the subject with caution.
REFLECTIONS
If I were to do this project again, I think I would have planned the structure differently. For example, I spent a larger chunk of time setting up the battleship game in python, but this had to be mostly re-written to fit a class when I wanted to use the OpenAI Gym environment. Next time, I will plan this better and look at what each piece of the puzzle requires so that the process can be a bit smoother.
In addition, documentation within code comes naturally, but during the process I would document my steps a bit better and as I do them. I found that trying to do the write-ups days after I had completed something was a bit challenging, and it was difficult to remember what exactly I did. If instead I did the write-up as I went, I could simply make a note every time I added a function, or changed the rewards parameter, and this process of the formal write-up would go much smoother because I would have already written the outline of methods.
Finally, I chose to do my project as a single, due to the online format and a few other factors. Next time, I think I would challenge myself to work with a partner or a group, and I think this would have brought a bit of a social aspect, and it would have been nice to have someone get excited about results with me as I go. With that being said, not I nor anyone could have planned for the pandemic or how it has affected each of us.
CITATIONS
Stable Baselines 3, uses pytorch https://stable-baselines3.readthedocs.io/en/master/ “Stable Baselines3 (SB3) is a set of reliable implementations of reinforcement learning algorithms in PyTorch.”
Open AI Gym environment https://towardsdatascience.com/creating-a-custom-openai-gym-environment-for-stock-trading-be532be3910e